你有沒有過這種經驗:某天凌晨三點,突然 PagerDuty 響了,Slack 被狂刷一堆訊息,「🔥🔥🔥 Database exploded again」。
然後你睡眼惺忪打開電腦,心裡默念:「希望是網路壞了,不是我壞了」。結果一查,CPU 100%、記憶體爆炸、API timeout。
你以為只是小吵,結果一看發現「已被封鎖」。感情直接瞬間跳空跌停,就像 CPU 直接爆到 100%,一點緩衝都沒有。
欸,這時候就知道 —— 監控不是選配,是救命工具。
如果平常有 Prometheus + Grafana 幫你盯著,你就能提早發現「欸,CPU 一直往上飆喔」、「流量開始不對勁了」。
不然等到出事,工程師只能用膝蓋硬猜,就像爸媽猜小孩為什麼叛逆一樣:永遠猜不中。
所以今天我們來聊聊 Prometheus + Grafana,外加那些 Exporters,怎麼讓你在職場的修羅場裡多活幾年。
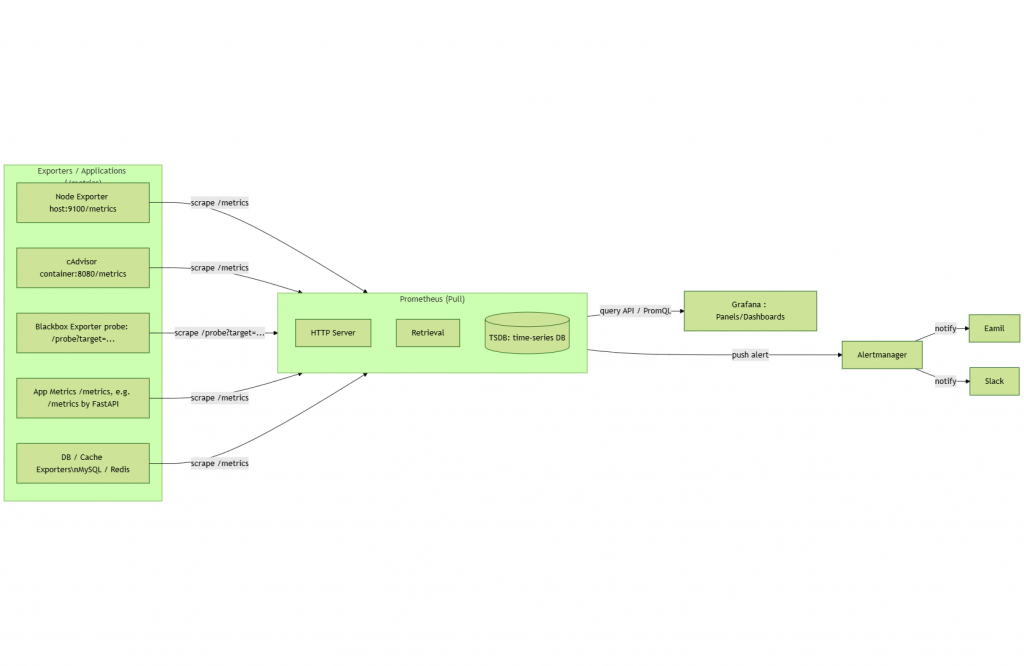
Prometheus 是監控系統界的「雞婆阿姨」,逢人就問「CPU 怎樣了?記憶體有沒有過勞?服務還活著嗎?」。
它靠「pull」模式,定時跑去別人家敲門收資料。
Prometheus 是 CNCF 的核心專案,功能是:
收集時間序列資料 → 存起來 → 用 PromQL 查 → 再丟給 Grafana 畫圖。
很像八卦群組的管理員:誰發生什麼事、什麼時間、跟誰有關,它都會幫你記下來。
特色:
一句話:Prometheus 就是監控世界裡那個「什麼都要知道」的鄰居阿姨。
市面上兩派:
Prometheus 的人生觀是「我來找你,不麻煩你來找我」。
聽起來很貼心,但實際上就是那種每天準時 15 秒來敲門借醬油的鄰居阿姨。你要是沒開門,她馬上在群組傳:「某某家今天可能有狀況」。
不過世界不可能完全照它的哲學走,像短命的 batch job,還沒被拉就掛掉了。這時就要用 Pushgateway,先把資料存起來,等 Prometheus 來收。
Prometheus 選 Pull,因為好處是:
/metrics endpoint,裡面列出各種指標。prometheus.yml,週期性地去拉取。範例 /metrics 長這樣:
# HELP http_requests_total The total number of HTTP requests
# TYPE http_requests_total counter
http_requests_total{method="GET", handler="/"} 1024
http_requests_total{method="POST", handler="/login"} 230
Prometheus 會把這些數據存成 label-based time series,方便後續查詢。
看到這個就像看健身紀錄:「今天深蹲 200 下,結果腰閃到」。
數字看似漂亮,其實背後一堆悲劇。
Prometheus 裡面自帶 TSDB,專門收 Metrics。
設計方式是 metric name + labels 唯一標識,每筆數據都跟時間戳綁一起。
會自動做壓縮與分片,方便快取與查詢
例如:
http_requests_total{method="GET", handler="/"} → [ (t1, 100), (t2, 120), (t3, 150)... ]
簡單粗暴,但很有效率。
存太久會爆炸,就像你硬碟裡還留著 2012 年的 MSN 聊天紀錄,一打開滿滿都是「在嗎?」、「不在」。佔空間、沒價值,還容易被現任翻到。
所以業界會搭 Thanos / Cortex 做長期存放。
可參考Blueswen 大寫的 Thanos
PromQL 是查詢語言,功能大概是「讓你當算命師」。
PromQL 是 Prometheus 的查詢語言,用來對時間序列進行運算。
PromQL 就像工程師專屬的塔羅牌,占卜對象不是戀愛,而是 CPU、QPS、Error rate。rate(http_requests_total[5m]) 看起來是數學公式,其實是工程師的水晶球。翻譯成白話就是:
——答案:會。
——解法:多開一台。
——心情:已經爆了,老闆還問為什麼。
例如:
rate(http_requests_total[5m]) → 過去 5 分鐘內的請求速率avg_over_time(cpu_usage[1h]) → 過去一小時的平均 CPU 使用率topk(5, http_requests_total) → 請求數最多的前 5 個路徑看這些數字,就像看股票走勢圖:「啊,這支要跌了」;結果你買進之後,它還是跌了。
Grafana 正是利用 PromQL 來繪製圖表。
Prometheus 的理念是 「一切皆可 Metrics」。
Prometheus 本體就像八卦阿姨,但她只聽得懂「自家方言」。那怎麼辦?就要靠 Exporter 當翻譯機。
MySQL、Redis、Node Exporter… 各種 exporter 就是把原本的「鬼畫符」資料翻成阿姨聽得懂的語言。
所以 Prometheus 本身很單純,但世界一點都不單純。😢😢
這時候就需要 Exporter—— 一種「翻譯器」,把系統狀態轉成 Prometheus 認得的格式。
常見的 Exporter 有:
監控 CPU、記憶體、磁碟、網路。
直接讀 /proc 和 /sys,就像醫生幫你驗血、驗尿一樣。
結果通常都不太好看:
「CPU 一直 90%,你是不是在跑挖礦?」
「記憶體只剩 200MB,你是誰還在跑 JVM?」
最基礎的 exporter,用來蒐集 主機層級的系統指標。
包括:
它會直接讀取 /proc、/sys 等系統檔案,並轉換成 Metrics。
Google 出品,專門監控容器。
它會告訴你:
用過的人都知道,看 cAdvisor 就像看工地監視器:「欸,那個 Pod 怎麼又倒了?」
它不是看內部,而是從外部測:
不同於 Node Exporter 與 cAdvisor 監控系統內部,Blackbox 會從外部去檢查:
有點像情侶關係:你以為內部很好,其實外部早就分手了。
像 MySQL、Postgres、Redis、MongoDB、Kafka,都有官方或社群的 Exporter。
它們會把系統的統計資訊轉成 Metrics,例如:
每次看這些數字,都有種「老闆,你確定我們要撐到雙十一嗎?」的無奈。
前面提到的 Node Exporter、cAdvisor、DB Exporter,那些大多是「系統層」或「基礎設施層」的監控。
但 Prometheus 最香的部分,其實是 應用層 Metrics —— 直接從程式邏輯裡吐出來的數據。
除了系統層與資料庫,應用程式自己也能暴露 /metrics。
常見的方式是透過 Prometheus SDK / Middleware:
prometheus-client
prometheus
prometheus-fastapi-instrumentator
這樣工程師自己也要坦白交代:
Prometheus 本身只能查數字,Grafana 才是那個「把數字變成圖表」的藝術家。
特色:
1. **資料來源**:支援 Prometheus、Loki、ElasticSearch、ClickHouse …
2. **Dashboard**:多種圖表(折線、Bar、Gauge、Heatmap)
3. **PromQL 查詢**:直接寫 PromQL 抓取 Prometheus 裡的數據
4. **告警(Alerting)**:在 Panel 上加告警條件
例如,你可以建一個 Dashboard:
Prometheus 內建的 Rules 可以定義告警條件,例如:
alert: HighCPUUsage
expr: node_cpu_seconds_total{mode="user"} > 0.9
for: 5m
labels:
severity: warning
annotations:
description: "CPU 使用率超過 90% 持續 5 分鐘"
一旦觸發,Prometheus 就會把告警送給 Alertmanager。
Alertmanager 功能:
半夜被 Alertmanager 搖醒,你懷疑人生,然後發現 Slack 紅點比股票跌停還慘。最後你不是修 bug,而是「怎麼讓它不要一直吵我」(通知規則)。
在業界,Prometheus + Grafana + Exporters 幾乎是 Kubernetes / 微服務的標配。
常見的使用方式:
/metrics
Cardinality = 不同 label 組合的數量。數字越大,Prometheus 要存的 time series 就越多。
Prometheus + Grafana + Exporter + Alertmanager,組合起來能幫你從主機、容器、應用,一路看到使用者體驗。
但說到底,監控不是讓系統不壞,而是讓你提早知道它快壞了。
就像感情不是永遠穩定,而是你能提早看到苗頭 ——「啊,她開始已讀不回了」。
別等系統倒了才說「為什麼沒人提醒我」。因為到時候,只有 Prometheus 會默默陪你熬夜。

